
코딩 노트
05-1 C언어가 제공하는 기본 자료형의 이해 본문
1. 자료형
자료형(data type)은 '데이터를 표현하는 방법'을 뜻함.
int는 그러한 자료형의 일종, 이러한 자료형이 미리 정의 되어 있기에 우리는 자료형의 이름을 이용해서 쉽게
메모리 공간을 할당할 수 있는 것임.

2. 기본 자료형(기본적으로 제공되는 자료형)의 종류와 데이터의 표현 범위
자료형 char는 1바이트(8비트)이므로 나타낼 수 있는 데이터의 종류가 '2의 8승은 256', 256개임.
따라서 -128부터 +127까지 표현하도록 정의된 자료형임.
C의 표준을 정하는 ANSI에서는 다음과 같은 정도로만 자료형의 크기를 표준화하고 있음.
"short와 int는 최소 2바이트이되, int는 short와 크기가 같거나 더 커야한다."
즉, 자료형 별 크기를 정확히 제한하고 있지 않음. 따라서 자료형 별 크기는 컴파일러마다 차이를 보임.
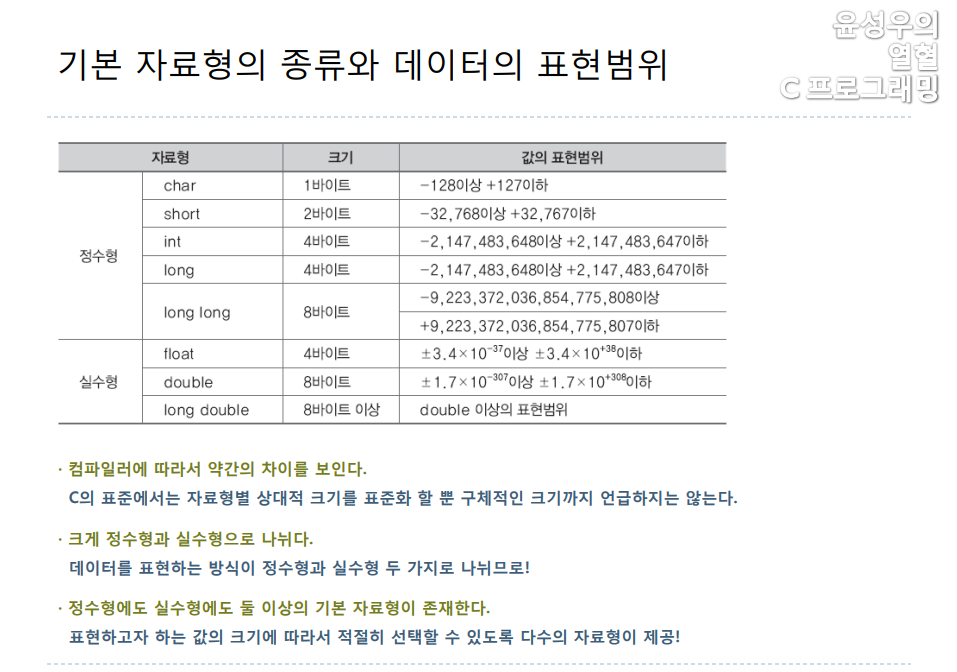
이렇게 많은 수의 자료형을 제공하는 이유는 무엇일까?
첫째, 데이터의 표현방식이 다르므로, 최소 둘 이상의 자료형이 필요하다.
자료형의 종류는 크게 정수 자료형과 실수 자료형으로 나뉘는데 이렇게 두 가지로 나눠놓은 이유는 컴퓨터가 정수와 실수를 표현하는 방식이 다르기 때문이다. 따라서 정수와 실수를 표현하기 위한 자료형이 각각 최소한 하나씩은 있어야 한다. 하지만 위의 표를 보면 자료형의 종류는 두 개가 넘는데, 많은 수의 자료형이 등장한 두 번째 이유가 있다.
둘째, 메모리 공간의 적절한 사용을 위해서 다양한 크기의 자료형이 필요하다.
예를 들어, 총 5,000개의 정수를 저장해야 한다고 가정해보자. 그런데 이 정수들은 short형으로 표현이 가능한 정수들이다. 따라서 이 정수들을 short형으로 표현해서 저장한다면, 총 5,000X2=10,000바이트가 소모된다. 반면, 이를 int형으로 표현해서 저장한다면, 이의 두배에 해당하는 바이트 수가 소모되어 그만큼 메모리를 낭비하는 결과로 이어질 수 있다. 즉, 메모리의 효율적 사용을 위해 다양한 크기의 자료형이 존재하는 것이다.
3. 연산자 sizeof를 이용하면 자료형의 크기를 확인할 수 있다.
메모리 공간에서 소모하는 메모리의 크기를 바이트 단위로 계산해서 반환하는 sizeof라는 연산자가 존재한다. 그리고 이 연산자의 피연산자로는 변수와 상수뿐만 아닌, 자료형의 이름도 올 수 있기 때문에, 이 연산자를 이용해서 자신이 사용하는 컴파일러의 자료형 별 바이트 크기도 확인할 수 있다.
· sizeof 연산자 사용방법
int main(void)
{
int num = 10;
int sz1 = sizeof(num); // 변수 num의 크기를 계산하여 sz1을 초기화
int sz2 = sizeof(int); // 자료형 int의 크기를 계산하여 sz2를 초기화
. . . .
}위의 코드에서는 sizeof 연산자의 피연산자를 모두 소괄호로 감싸줬는데, 이 소괄호는 int와 같은 자료형의 이름에는 필수지만, 나머지 피연산자에 대해서는 선택적이다. 하지만 소괄호를 사용하는 것이 문장을 이해하는데 도움이 되기 때문에, 피연산자의 종류에 상관없이 무조건 소괄호를 사용하는 것이 일반적이다.
sizeof 함수? sizeof 연산자!
대부분의 프로그래머들이 sizeof 연산자의 피연산자를 소괄호로 감싼다. 그러다 보니 sizeof 연산자를 함수로 오인하는 경우가 종종 있는데, 일부 문서에서조차 이러한 실수가 눈에 띄므로 주의가 필요하다. sizeof는 함수가 아닌 연산자이다.

4. 정수를 표현 및 처리하기 위한 일반적인 자료형의 선택
정수를 저징할 변수의 자료형을 선택할 때, 가장 먼저 생각할 문제는 '저장하고자 하는 값의 범위'이다. 예를 들어서 short형 변수가 저장할 수 있는 값의 범위는 -32,768이상 +32,767이하이다. 이의 범위를 넘어서는 정수를 저장하려면 int형 변수를 선언해야 한다. 그렇다면 저장하고자 하는 값이 -32,768 이상 +32,767이하의 범위 내에 든다면, int형 변수를 대신해서 short형 변수를 선언하는 것이 더 효율적이라고 말할 수 있을까? 그건 상황에 따라 다르다. 즉, 값의 범위만 가지고 short냐 int냐를 결정할 수 없다는 뜻이다.

일반적으로 CPU가 처리하기에 가장 적합한 크기의 정수 자료형을 int로 정의한다. 따라서 int형 연산의 속도가 다른 자료형의 연산속도에 비해서 동일하거나 더 빠르다. 이렇듯 int형 연산이 CPU가 성능을 내기에 가장 좋은 연산이다 보니, int보다 작은 크기의 데이터는 int형 데이터로 바꿔서(형 변환)연산이 진행된다.
연산의 대상이 되는 변수를 선언하는 경우에는, 특히 연산의 횟수가 빈번한 경우에는 저장되는 값의 크기가 작더라도 int형 변수를 선언하는 것이 좋다.
그렇다면 char형 변수와 short형 변수는 불필요한 건가라고 생각할 수 있는데 데이터의 양이 많아서 연산속도보다 데이터의 크기를 줄이는 것이 더 중요한 데이터들에 대해서는 char형 변수와 short형 변수가 유용하게 사용된다.
5. 실수를 표현 및 처리하기 위한 일반적인 자료형의 선택
float냐 double이냐를 결정할 때, 값의 표현범위는 중요한 요소가 되지 않는다. 실수 자료형의 선택에 있어서 가장 중요한 요소는 정밀도이다. 여기서 말하는 정밀도는 '오차가 발생하지 않는 소수점 이하의 자릿수'를 뜻한다. 오차도 데이터표현에 사용되는 바이트의 수가 커지면 줄어들기 마련이다.
아래 표에서 보이듯이 double형의 경우, 소수점 이하 15자리까지는 오차가 발생하지 않음을 보장하니, 이 정도면 정밀도가 높은 편이라 할 수 있다. 근데 프로그래밍을 하다 보면 정밀도까지 따져 가면서 자료형을 선택하는 것이 그리 쉬운 일은 아니다. 따라서 정수 자료형에서는 int를 보편적으러 선택하듯이, 실수 자료형에서도 보편적으로 선택하는 자료형이 있는데 그것이 바로 double형이다. double이 보편적 선택이 될 수 있는 이유는 float보다 정밀도가 높으면서도, long doule보다는 부담이 덜 되기 때문이다.
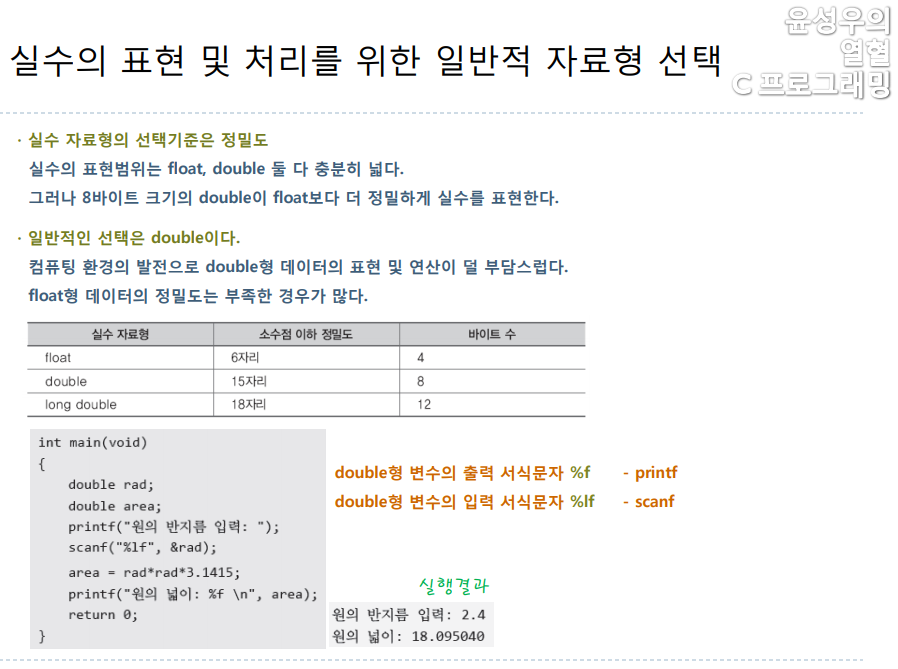
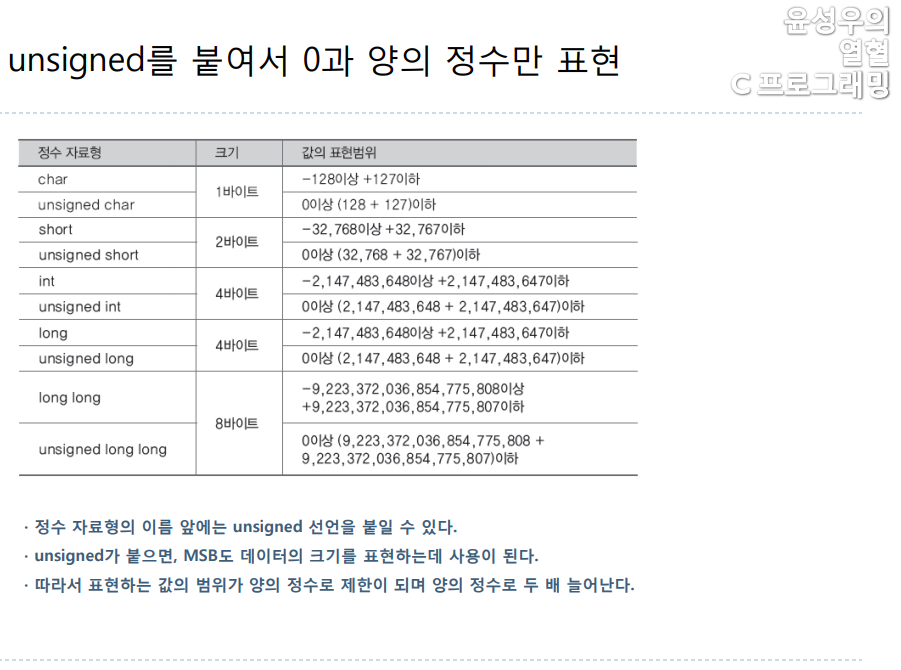
6. unsigned를 붙여서 0과 양의 정수만 표현하게 할 수 있습니다.
정수 자료형의 이름에 한해서 unsigned 선언을 추가하면, 0 이상의 값만 표현하는 자료형이 되어서, 표현할 수 있는 값의 범위가 양의 정수 방향으로 두 배 더 넓어지게 된다. 그렇다면 unsigned를 붙이면 어떠한 일이 벌어지는 것일까? 기본 자료형의 가장 왼쪽 비트인 MSB는 데이터의 부호를 결정짓는데 사용한다고 하였는데, unsigned를 붙여버리면 MSB 조차 값의 크기를 나타내는 비트로 사용하게 된다. 다시 말하면 +, -의 기준이 사라져서 표현하는 모든 값은 0 이상의 값이 되는 것이다.
참고로 정수 자료형의 이름 앞에는 signed 선언을 추가할 수 있는데, 이 키워드를 붙인다고 해서 의미가 변하는 것은 아니다. 즉 int와 signed int는 같은 선언이며 short와 signed short도 같은 선언이다. 따라서 대부분의 프로그래머들은 signed라는 키워드를 생략한다.
다른 정수 자료형들과 달리 char는 signed char와 다른 선언일 수도 있다. char를 unsigned cahr로 처리하는 컴파일러도 존재하기 때문이다. 이런 이유로 char형 변수를 선언해서 음의 정수를 저장하는 경우에는 signed 선언을 추가하기도 한다. 지금 설명한 unsigned 선언을 추가하여 정수 자료형의 종류를 구분하면 다음과 같다. 물론 char는 signed char라고 가정하여 작성한 표이다.
'C' 카테고리의 다른 글
| 05-3 상수에 대한 이해 (0) | 2021.05.05 |
|---|---|
| 05-2 문자의 표현방식과 문자를 위한 자료형 (0) | 2021.05.05 |
| 04-3 비트 연산자 (0) | 2021.02.19 |
| 04-2 정수와 실수의 표현방식 (0) | 2021.02.19 |
| 04-1 컴퓨터가 데이터를 표현하는 방식 (0) | 2021.02.18 |



